一、三种常见的消息队列
RabbitMQ
Erlang语言开发的,轻量级的,基于队列模式的消息队列,性能较差(相比于Kafka, RocketMQ),不支持消息的大量堆积。
RocketMQ
阿里用Java开发的,基于发布订阅模式的消息队列,性能,稳定性久经考验,但与Kafka相比,在国际上不够流行,与周边生态系统的兼容和集成要略逊一筹。
Kafka
LinkedIn用Java和Scala开发的,基于发布订阅模式的消息队列。在国际上使用广泛,与周边生态系统具有良好的兼容性。设计上大量使用批量和异步思想,这使得Kafka有着超高的性能。
但是Kafka这种异步批量的设计带来的问题是,它的同步收发消息的响应延迟比较高,在Kafka的很多地方都会使用“先攒一波再一起处理”的设计。
| 种类 | 优势 | 劣势 |
|---|---|---|
| RabbitMQ | 1. 轻量级,拿来即用 | 1. 相对而言性能较差 2. 不支持消息的大量堆积 |
| RocketMQ | 1. 性能高(十万级别) 2. 稳定性好 3. 实时性好 |
1. 在国际上不够流行,与周边生态兼容性差 |
| Kafka | 1. 性能高,在消息量大的系统中性能优于RocketMQ 2. 稳定性好 3. 在国际上很流行,与周边生态兼容性好 |
1. 消息量不大的系统中同步收发延迟高 |
一般来说,RocketMQ常被用于在线业务, Kafka常被用于离线业务。
二、两种消息模型
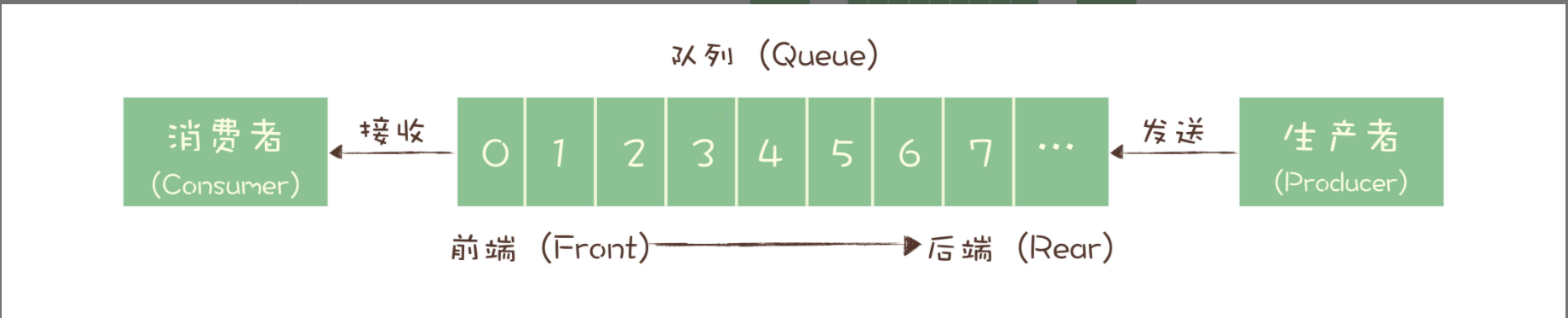
队列模型
发布订阅模型
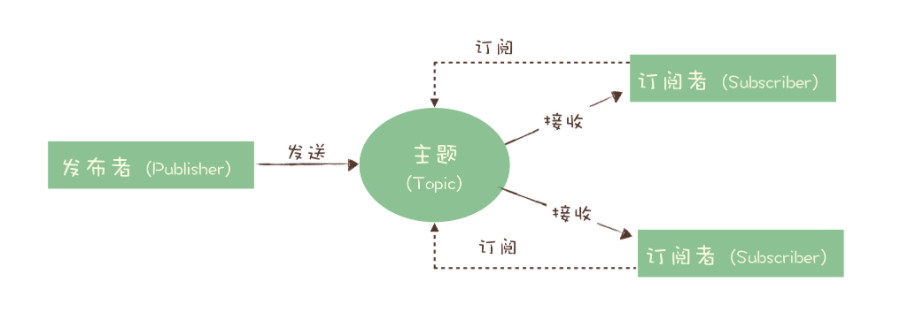
上面两种模型的区别: 一份数据能不能被多次消费。
三、基本概念
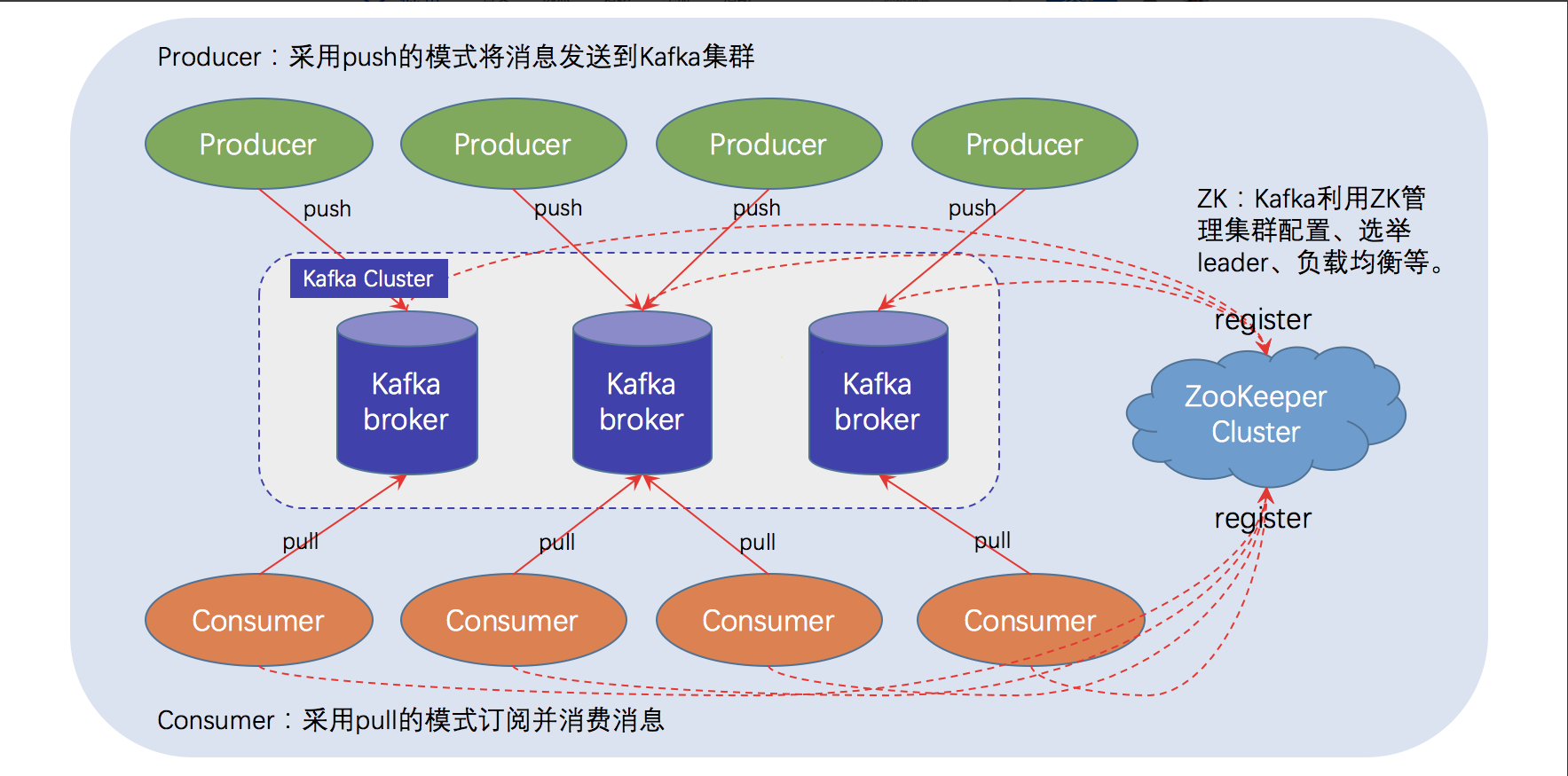
Producer
消息生产者, 负责将消息发送到Broker。
Consumer
消息消费者,负责实际消费消息。
Consumer Group
一个Consumer Group对应一份订阅,它需要消费一个Topic下所有Partition内的全部消息。Topic内的每一条消息会被广播给所有订阅了该Topic的Consumer Group, 但是一个Consumer Group中只有一个Consumer可以消费该消息。
Broker
Kafka server, 充当生产者与消费者之间的一个中介,负责存储和处理消息。
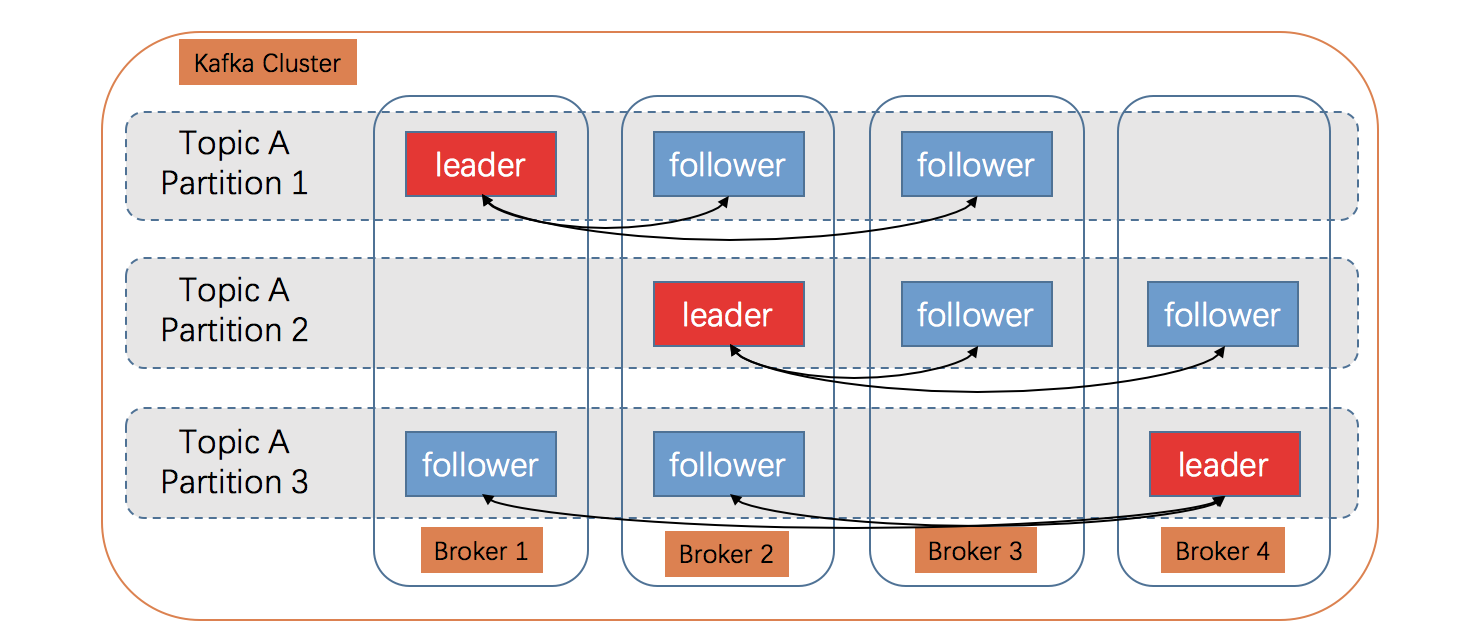
Topic
逻辑上的一个概念,没有对应的物理存在。可以理解为对消息的一个归类,生产者生产消息和消费者消费消息都需要指定Topic。
Partition
与Topic一样,Partition也是一个逻辑概念,没有对应的物理存在。一个Topic下可以有多个Partition,出于负载均衡的考虑,同一个 Topic 的 多个Partition 会相对均匀的分布在 Kafka 集群的多个 Broker 上。
生产者发送到Topic的消息会按照分区规则发送到具体的某一个Partition内,一个Partition内的消息是严格有序的,即先到达Partition的消息一定比后到达的消息先消费。
由于消息确认机制的限制,一个Partition内的消息只会给消费组内的一个特定Consumer实例消费,如果消费组内的Consumer数量多于Topic下Partition的数量,那么多出来的Consumer将分配不到Partition,从而消费不到任何消息。
Partition Replicas
为了提升Partition的可用性,Kafka还设计了Partition Replicas(分区副本)。一个Partition包含了多个Partition Replicas,在任意一个时刻,只有一个Partition Replica(Leader)对外提供读写功能,其他的Partition Replica(Follower)只负责从Leader同步数据,当Leader宕机后,就会选择一个Follower成为新的Leader。一个Partition的多个Partition Replicas会相对均匀的分布在Kafka的多个Broker上。
Log
一个分区副本对应一个Log(日志), Log在物理上对应一个文件夹,Log中存储了当前分区副本中的消息以及索引等数据。
Log Segment
为了防止Log过大,Kafka又引入了Log Segment(日志分段)的概念,将一个巨型文件平均分割成多个相对较小的文件,便于消息的清理和维护。每个Log Segment对应一个日志文件和两个索引文件,以及其他的可能文件。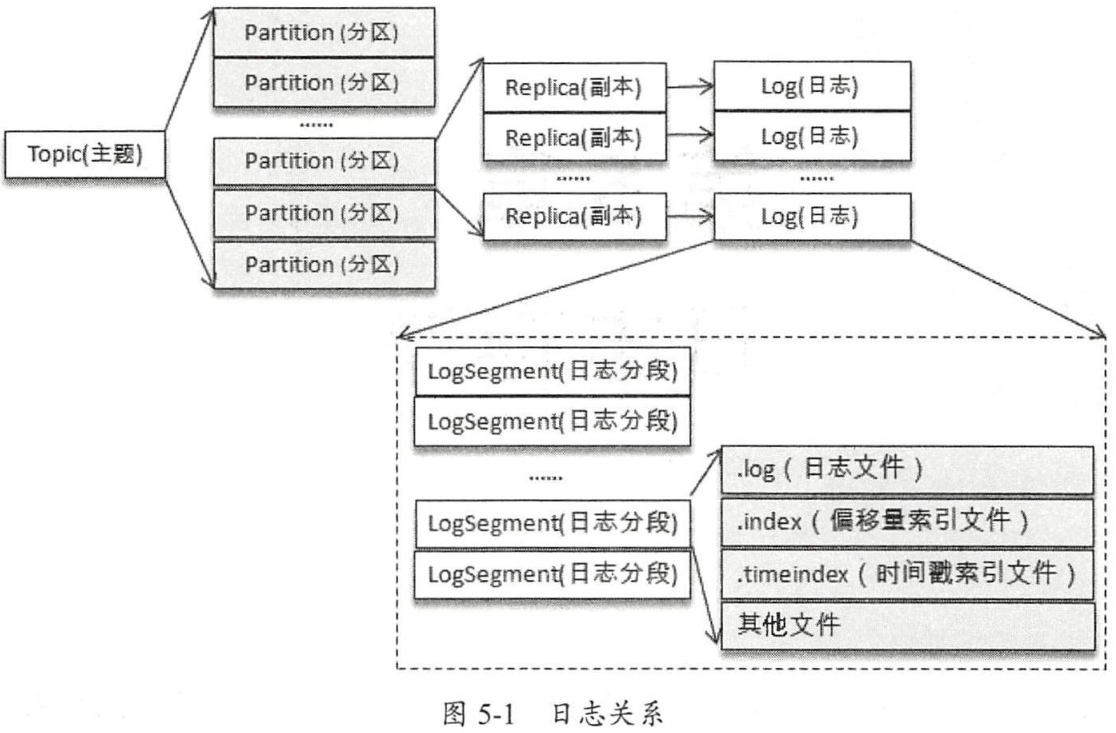
四、分区副本同步细节
AR/ISR/OSR
AR(Assigned Replicas): 一个分区的所有副本。
ISR(In-Sync Replicas): 与Leader 副本保持一定程度同步的副本(包括Leader副本本身)
OSR(Out-of-Sync Replicas):与Leader副本同步滞后过多的副本。
AR = ISR + OSR
Leader副本负责维护和跟踪ISR列表中所有副本的滞后状态,当有副本的滞后状态超过了replica.lag.time.max.ms配置的值时,会将其从ISR列表中剔除并转移至OSR列表中,当OSR中副本的滞后状态小于replica.lag.time.max.ms配置的值时,会将其移到ISR列表中。当Leader副本发生故障,将会从当前的ISR列表中选择新的Leader.
acks 性能和可靠性的考虑
request.required.acks是生产者客户端中的一个及其重要的配置参数,它描述的是当生产者将消息发送到Broker端时,消息需要同步到多少个分区副本才算做消息发送成功,才会返回响应给生产者。
request.required.acks = 1, 1为默认配置。表明消息只要成功写入Leader副本就算发送成功。考虑这样一个场景: 当消息成功写入Leader副本,没来得及同步到其他的Follower副本时Broker崩溃,这样消息就丢失了。
request.required.acks = 0,表明生产者不需要任何等待,只要消息发送出去就表明成功。0的配置下,如果消息从发送到写入,出现了任何的问题,那么消息都会丢失。0的配置下,可以达到最大的吞吐量。
request.required.acks = -1 (all),表明生产者发送消息后,需要等待消息成功写入到所有的ISR列表中的分区副本,才算写入成功。该配置下,消息的吞吐量是最小的,但可靠性也是最高的。
HW控制消息可见性
每一个分区副本都顺序记录了所有的消息,每一条消息都有一个Offset来标记他在Log中的位置。Log序列中有两个特殊的标记HW, LEO.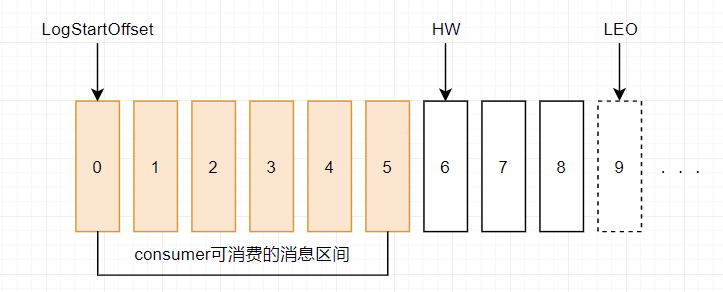
LEO(Log End Offset):当前日志文件中,下一条待写入的日志的offset。
HW(High Watermark): 俗称高水位,它标识了一个特定的消息偏移量,消费者只能拉取到HW之前的消息。HW等于ISR列表中所有的分区副本的最小的LEO值。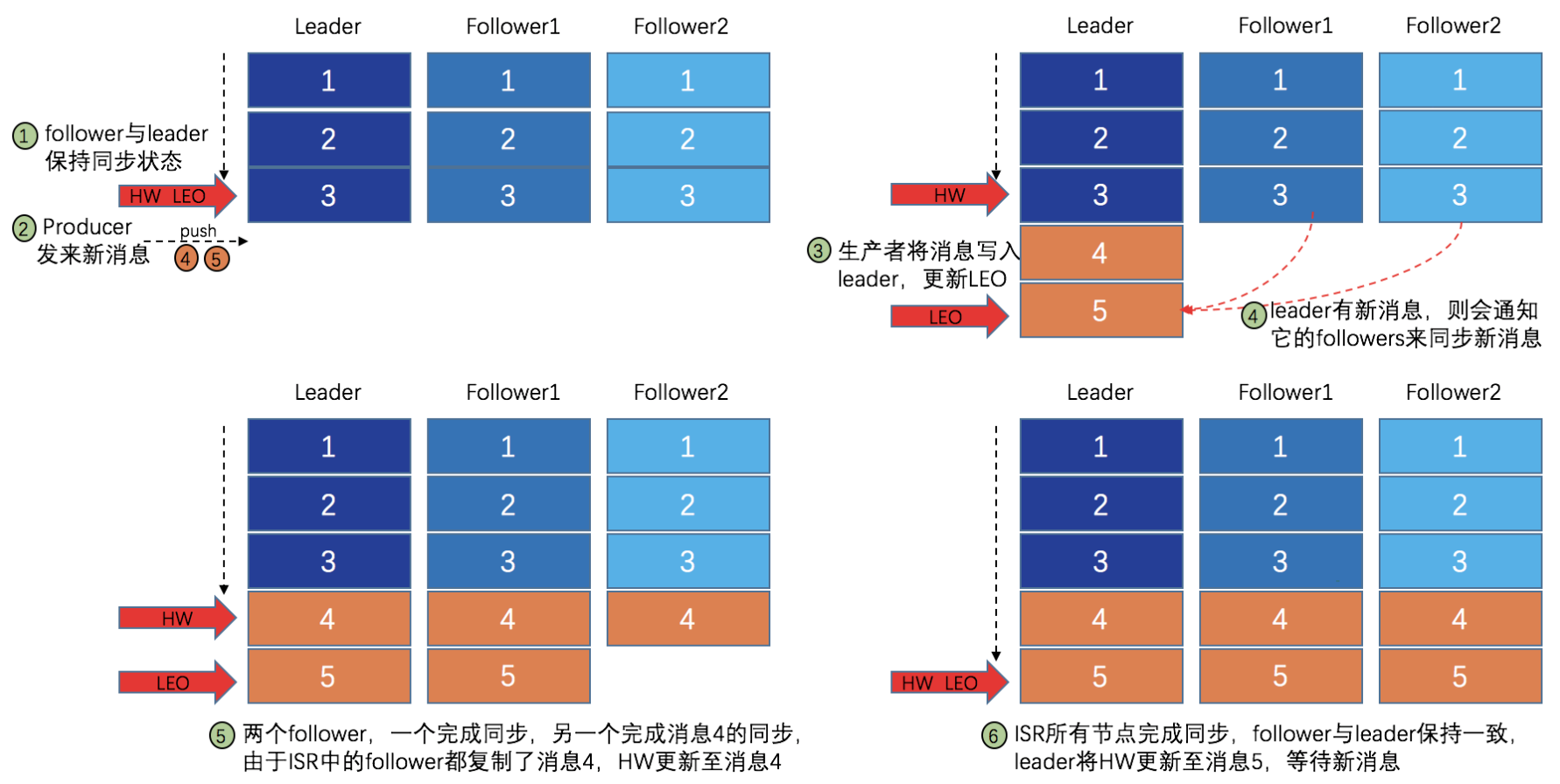
五、Kafka日志存储细节
三种版本的消息格式
V0
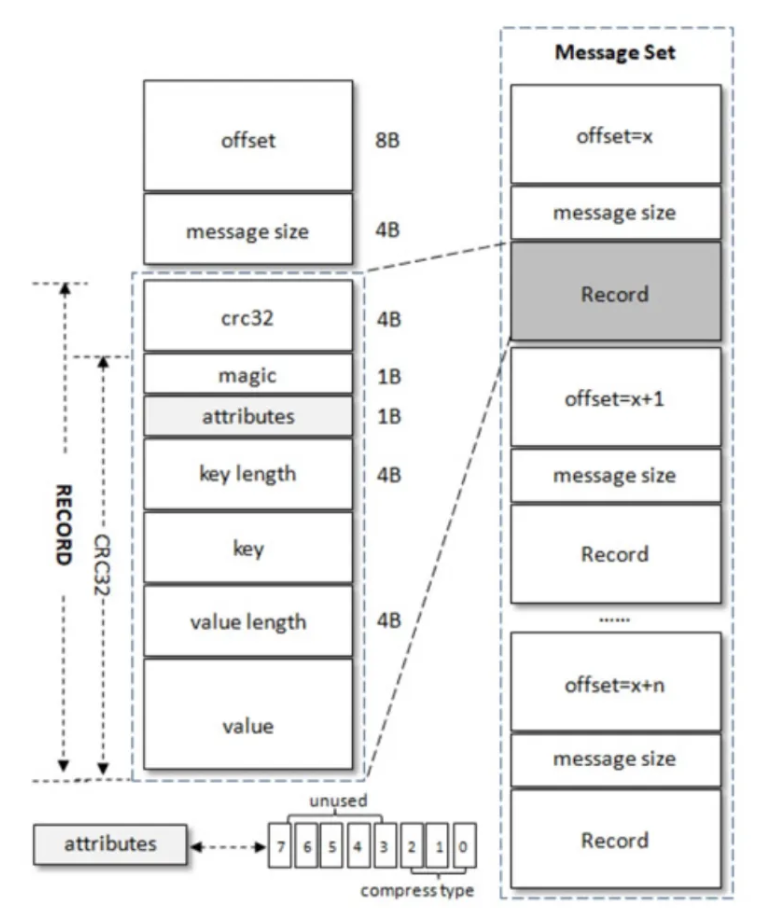
offset: 消息在分区中的偏移量,是一个逻辑值,而非实际的物理值。
message size: 表明消息的大小。offset和message size一起被称为日志头部(LOG_OVERHEAD)
crc32: crc32检验和,校验范围为magic至value之间。magic:消息格式版本号,在V0版本中该值为0.attributes: 消息的属性, 总共一个字节,低三位表示压缩类型,其余位保留。0:None, 1:GZIP, 2:SNAPPY, 3: LZ4key length: key的长度前缀,若为-1表明,没有设置keykey: key的实际值,可选value length: value的长度前缀value: 消息实际值
crc32+magic+ attributes+ key length+key+ value length+value整体被称为RECORD.
V1
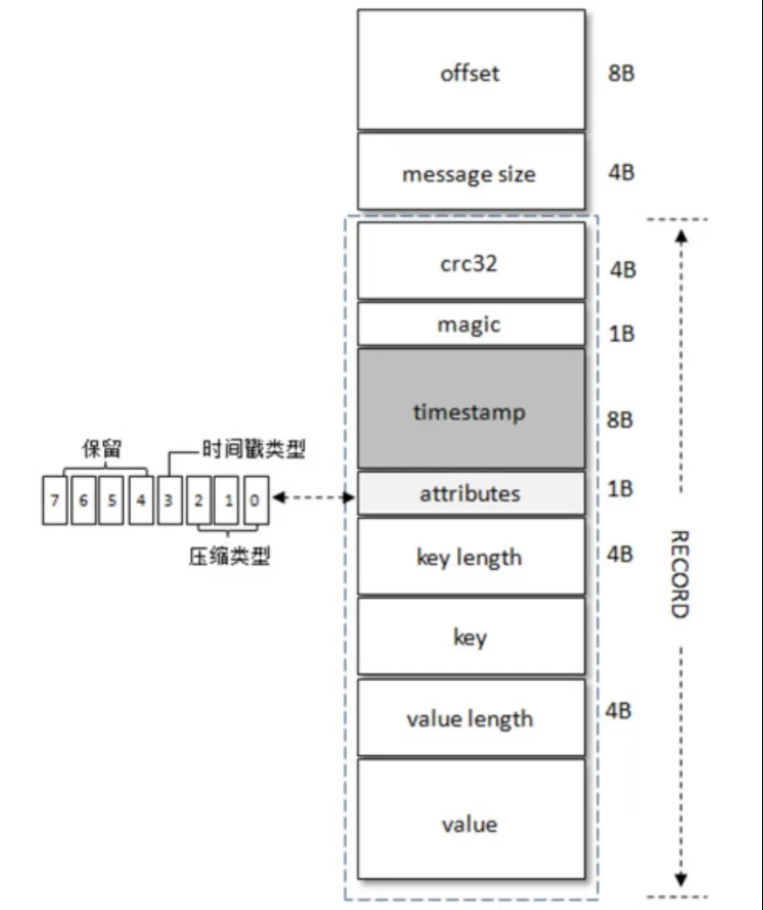
V1版本的消息格式与V0版本的消息格式大体相同。不同点在于V1版本在magic和attributes之间增加了一个8字节的timestamp字段,并且attributes的第四个Bit也别利用了起来,用来表明存储的时间戳类型。0: CreateTime, 1:LogAppendTime
V2
V2版本的消息格式对比V0和V1版本的消息格式改动很大,并且还参考了Protocol Buffer而引入了变长整数(Varints) 和ZigZag编码, 这里简单介绍下Varints和ZigZag.
VarInts
对于一个整形数字,一般使用 4 个字节来表示一个整数值。但是经过研究发现,消息传递中大部分使用的整数值都是很小的非负整数,如果全部使用 4 个字节来表示一个整数会很浪费。比如数字1用四字节表示就是这样:00000000 00000000 00000000 00000001
对较小整数来说,这种固定字节数编码很浪费bit。所以人们就发明了一个类型叫变长整数varint。数值非常小时,只需要使用一个字节来存储,数值稍微大一点可以使用 2 个字节,再大一点就是 3 个字节,它还可以超过 4 个字节用来表达长整形数字。
其原理也很简单,就是保留每个字节的最高位的bit来标识后一个字节是否属于该数字,1表示属于,0表示不属于。
示意图如下: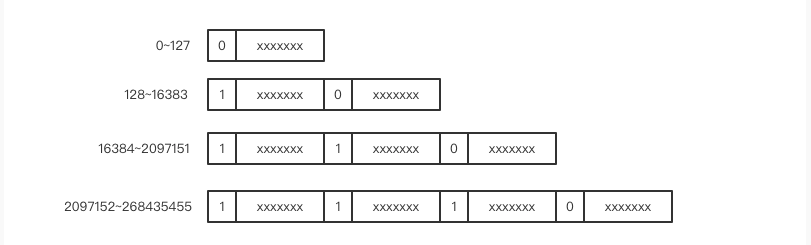
由于大多数时候使用的是较小的整数,所以总体上来说,Varint编码的方式可以有效的压缩多字节整数。
那么对于负数怎么办呢?大家知道负数在计算机中是以补码的形式存在的。
1 | 10000000 00000000 00000000 00000001 // -1的原码 |
所以-1在计算机中就是11111111 11111111 11111111 11111111 ,如果按照Varint编码,那么需要6个字节才能存的下,但是在现实生活中,-1却是个常用的整数。越大的负数越常见,编码需要的字节数越大,这显然是不能容忍的。为了解决这个问题, 就要使用ZigZag编码压缩技术了。
ZigZag
zigzag 编码专门用来解决负数编码问题。zigzag 编码将整数范围一一映射到自然数范围,然后再进行 varint 编码。
1 | 0 => 0 |
zigzag 将负数编码成正奇数,正数编码成偶数。解码的时候遇到偶数直接除 2 就是原值,遇到奇数就加 1 除 2 再取负就是原值。
六、Kafka如何实现高性能
1. 批量异步处理
在Kafka的设计中大量采用“攒一波再一起处理”的思路,在有大量频繁消息需要处理的系统中,这种思想可以极大的减少网络IO的次数,从而提高吞吐量,提升性能。
2. 线性(顺序)写
Kafka的模型天然的就是顺序写,顺序写磁盘和随机写内存的性能相当。
有关测试表明,一个由 6 块 7200 rpm 的 RAID-5 阵列组成的磁盘簇线性(顺序)写入速度可以达到 600MB/s,而随机写入速度只有 100KB/s,两者性能相差6000倍。操作系统可以针对线性写做深层次的优化。
涉及到数据持久化的存储系统一般都会利用顺序写来提升性能,如MySQL的redo log
3. 页缓存(PageCache)
虚拟内存是现代操作系统非常重要的一个机制,它将物理内存中的页帧当做磁盘上的页的缓存,页和页帧的对应关系由存在于物理内存中的页表维护,页帧中的内容会在程序的执行过程中按需换入换出。
4. 零拷贝(Zero-Copy)
1 | ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count) |
系统调用 sendfile() 通过 DMA 把硬盘数据拷贝到 kernel buffer,然后数据被 kernel 直接拷贝到另外一个与 socket 相关的 kernel buffer。这里没有 用户态和核心态 之间的切换,在内核中直接完成了从一个 buffer 到另一个 buffer 的拷贝。
如果不使用Zero Copy: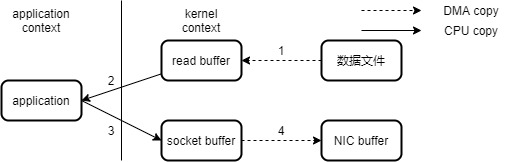
使用Zero Copy: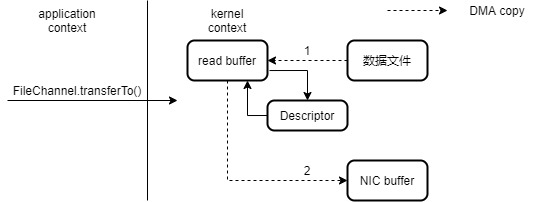
七、常见问题探讨
如何保证不丢消息?
在生产阶段,需要捕获消息发送的错误,并重发消息。
在存储阶段,通过配置刷盘和复制相关的参数,让消息写入到多个副本的磁盘上,来确保消息不会因为某个 Broker 宕机或者磁盘损坏而丢失。
在消费阶段,需要禁用自动提交offset,在处理完全部消费业务逻辑之后,再发送消费确认。
如何保证消息有序?
消息有序的概念: 先到达的Broker的消息一定比后到达的消息先消费。
Kafka只能保证Partition内消息的有序,如果需要全局严格有序,必须采用单Producer,单Partition的Topic,单Consumer的架构。
实际业务中,一般不会要求全局有序,都是某个业务对象的消息有序即可满足要求。这种时候只需要将同一个业务对象相关的消息发送到同一个partition即可。比如使用消息队列分发MySQL binlog的场景,只需要将同一个表同一条记录的所有消息发送到同一个Partition (取模或者一致性Hash)就可以保证在大部分情况下的有序。
如何处理消息重复?
现在消息系统一般提供at lease once的消费保证,消息有可能重复,这就需要消费端实现幂等消费
消息中编码唯一ID,在消费端拿到消息后,先存入本地消息表,利用数据库的唯一约束来实现
利用Redis来实现幂等校验
为更新语句设置条件
消息堆积怎么办?
检查消费端是否有消费错误,导致一直重试从而阻塞了Partition后续消息的消费
扩容Partition数量和消费者实例的数量,扩充消费者线程数,增大消费速度
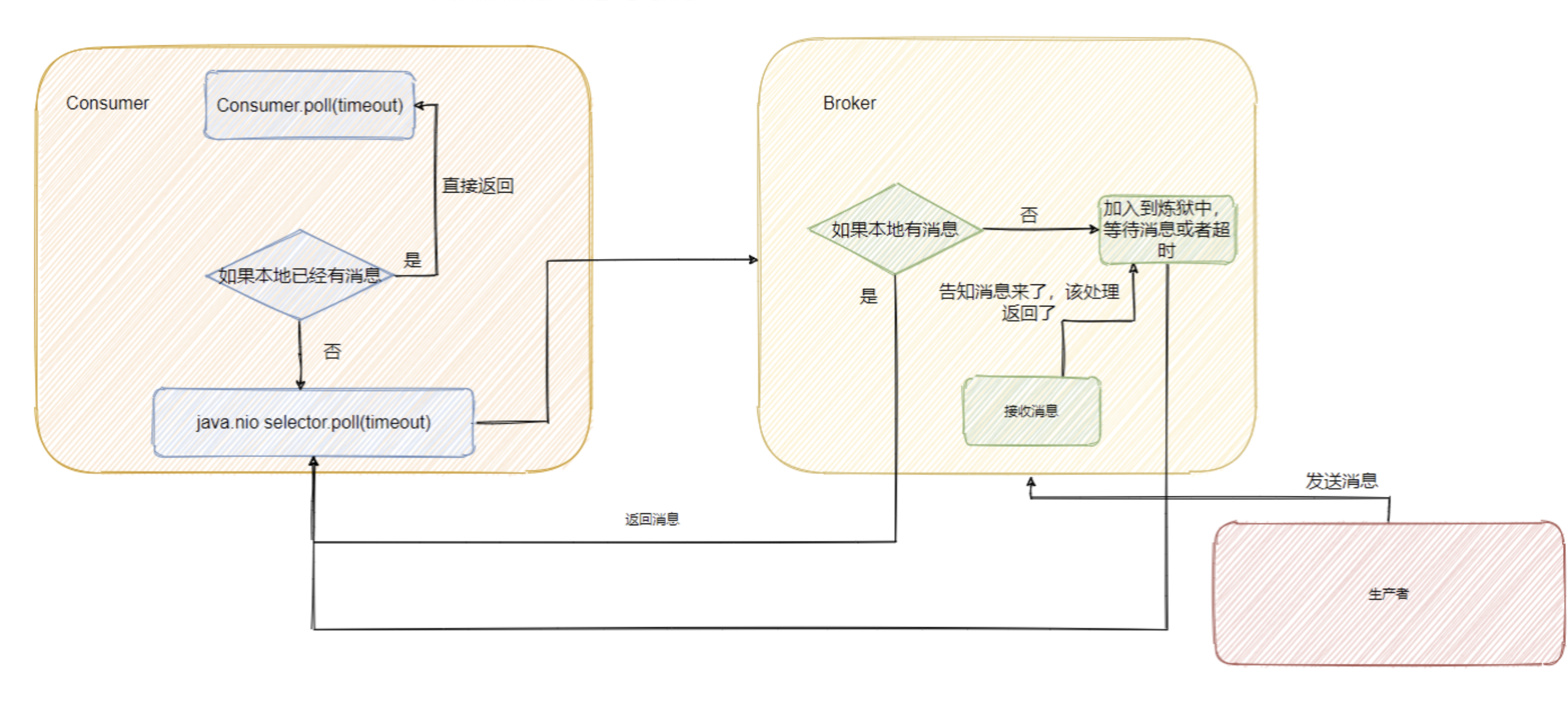
是推还是拉?
拉,Kafka Consumer采用长轮询的方式去Broker端拉取消息,如果Broker端有消息就直接返回,如果没有消息则等待指定时间,如果等待过程中消息来了,则带着消息返回,否则超时,未拉取到消息。